Persistent storage
Previous: Tracing
Overview
Storage is a module for storing blocks of data persistently at runtime. This data may
include individual configuration parameters written once after a software update, or runtime data
updated throughout the device lifetime by user applications or by other OpenBSW modules. The data
can be stored to various kinds of storage devices such as flash or EEPROM.
Plain flash memory can typically only be written after being erased first and both the write and the erase operations work at a certain granularity (e.g. 512 byte pages for writing and 4096 byte sectors for erasing). In contrast to that, EEPROM supports writing without erasing and allows writing individual bytes.
When only flash is available in a microcontroller, the behavior of an EEPROM can be emulated in software while in the end storing on flash (“flash-EEPROM emulation”). The simplest way to do this safely is to allocate two flash sectors for each data block and alternating (“swapping”) between the two on each write. Flash endurance has to be kept in mind though, in order to not run out of erase cycles too quickly.
The storage API should take care of most of this complexity by providing a unified interface for storing to different storage devices. Additionally, it ensures safe sharing of physical storage devices between users by preventing race conditions and data layout overlaps.
It’s most suitable for use cases where data should be copied (“mirrored”) to RAM for modification. It might not be ideal for loading read-only, memory-mapped data or in case copying must be avoided to save memory or for performance reasons.
Features
reading/writing a block of data, identified by a unique ID
maximum size for each block configured in a header file
partial reading/writing with variable starting offset and length
optional error detection (supported also when reading partially)
can read to or write from multiple, separate RAM buffers at once
support for various physical storages:
EepStoragefor EEPROM-like storage devices andFeeStoragefor (SW-based) flash-EEPROM-emulation, and more to be added
Design
Basics
Data classes:
StorageJob: represents a read/write operation and holds the job details (block ID, buffers, offset, callback, result); passed around from one storage to anotherLinkedBuffer: holds a buffer (anetl::spanassociated with a C-array) for reading or writing, can be linked together with other buffers
Grouping the job details into a data object provides flexibility and code reuse by having a single interface that operates on the data. Jobs can be put into linked lists, making it easy to maintain internal lists for queuing and bookkeeping. By allowing the buffers to be linked together also, they are easy to pass around in variable numbers while keeping the interface concise.
Storage classes:
IStorage: interface implemented by the “storages”; it has only one abstract method:void process(StorageJob& job)MappingStorage: delegates incoming jobs to “outgoing” storages, maps incoming block IDs to outgoing block IDs used by the delegatesQueuingStorage: when called, switches to the specified task context and then forwards the job to a delegate storage; also takes care of queuing when the delegate is busyEepStorage,FeeStorage: low-level storages that take care of managing the data layout and error detection; might use platform-specific drivers for the actual device access
When the process() method is called, the corresponding storage will execute the job and finally
deliver the result by running the provided callback. There can be a tree of storage classes where
one storage passes the job down to a delegate, and one of them eventually finishes it by running
the callback.
Storages are kind of plugins that can be added, removed or rearranged depending on the project needs. The “storage system” setup should stay fixed after startup and not change during normal runtime. This document discusses mainly the “demo” setup shown in the diagram below. Whenever other setups are discussed, it will be mentioned specifically.
![component User
component MappingStorage
component [QueuingStorage] as EepQueuingStorage
component [QueuingStorage] as FeeQueuingStorage
component EepStorage
component FeeStorage
User --> MappingStorage
MappingStorage --> EepQueuingStorage
MappingStorage --> FeeQueuingStorage
EepQueuingStorage --> EepStorage : In driver context
FeeQueuingStorage --> FeeStorage : In driver context](../../../_images/plantuml-7478e88fb5feb0832cc357661410d0a5f7ace680.png)
Note that both QueuingStorage objects run their delegates in the same task context (referred
to as “driver context”), but each could be configured with a different context as well if needed.
Preparing a job
In order to read or write data, users need to:
allocate a
StorageJobobjectinitialize it with the desired parameters: the job type (read or write), the block ID, the RAM buffers to use, and the asynchronous callback that should be run in the end
optionally specify a read/write offset for partial access
pass the job to
IStorage::process()and wait for the callback
Things to consider:
the callback must be of type
void callback(StorageJob& job), wherejobis the original job provided by the user, with the job result available viajob.getResult()orjob.hasResult()the job object or the associated
LinkedBufferobject(s) must not get deleted (e.g. go out of scope) until after the callback has returnedit’s forbidden to modify a job or the associated read/write buffers while the job is ongoing
it’s forbidden to call
process()again for an already ongoing joban ongoing job cannot be cancelled
there’s no upper limit on how long the processing can take; in case the application cannot wait longer than a certain period of time, it needs to go into an error state and not do a retry
in a multi-user system it should be assumed that the callback won’t be run in the user context, meaning that potential race conditions need to be considered
if multiple jobs are ongoing at once, users shouldn’t expect them to finish in any specific order: even though FIFO order is most likely, it’s not guaranteed because errors and different task priorities can affect the order
when
process()returns, it’s possible that the callback was already run directly in the same task context (or in a higher priority task), so if a flag is needed to maintain the job state, it’s important to set it before callingprocess()and not after, otherwise a flag value set inside the callback might immediately get overwritten
Warning
An additional limitation present in restricted, single-user systems is that users might not
be able to trigger a lot of follow-up jobs directly inside the callback, even if sending just one
job after another. When users call a low-level storage such as EepStorage directly without a
context switch, then the callback function is also run in the user context. In this case, when
triggering another job inside the callback, it doesn’t return immediately but recurses deeper
until reaching a “base case” in which no more jobs are sent. If the recursion is too deep, stack
memory will eventually run out and cause a crash. In multi-user systems this isn’t a concern
because the library protects against such recursion with internal asynchronous calls.
Providing the RAM buffers
RAM buffers to copy to/from must be provided as LinkedBuffer objects, each with
an etl::span inside. Buffers can be linked together using LinkedBuffer::setNext method
to form a list of buffers, each associated with a separate RAM-area. This provides flexibility in
choosing which RAM location should correspond to which part of the block, in effect dividing the
block into parts. Storages may also use this mechanism internally to attach headers or footers
before or after the actual data.
Sending a job to the mapper
When MappingStorage::process() gets called, MappingStorage (also called “mapper”) checks
the provided block ID (StorageJob::getId()) and uses this to find the correct entry in the
MappingConfig table, which contains all available IDs and the corresponding outgoing storages.
It then uses the configured outgoingIdx to find out which storage is assigned for the block and
passes the job to it.
Receiving a response
After one of the storages has processed the job (i.e. it has read or written the data and checked for errors), it will run the user-provided callback. It will do this directly in its own task context (different from the user context in the demo setup), so users need to be aware of race conditions in case there’s any data shared between the user context and the driver context. In the callback the job result, type, block ID and the read size (if reading) can be checked and handled accordingly. This can mean, for example, setting some internal state variables to control the application logic: in case of success, continue to the next step, otherwise go into an error state.
In case of error (i.e. StorageJob::hasResult<StorageJob::Result::Error>() returns true),
triggering a retry should not be necessary. An error is usually caused by mistakes in the
configuration, integration code, application code or inside the storage module itself. This means
that retries will probably fail too and just cause unnecessary system load. Or it might eventually
succeed but make it harder to detect and analyze the original problem. An error could also indicate
hardware failure, but in that case a retry might cause further data loss, so it’s preferable to go
into an error state instead. In the end though it’s up to the user to decide what to do in case of
error.
Thread safety
As already mentioned, users are responsible for handling any race conditions in the asynchronous
callback. They can be run in different task contexts: most commonly in the user or the “driver”
context, but it depends on the storage setup and could be any context. MappingStorage and
QueuingStorage are thread-safe, meaning that users from different tasks can share them without
having to worry about race conditions. StorageJob is partially thread-safe, excluding the
methods init(), initRead() and initWrite() that are supposed to be called by only one
user in one task context when preparing the job. The low-level storages EepStorage and
FeeStorage provide no thread safety at all when called directly.
Advanced: mapper internals
As mentioned before, when MappingStorage::process() gets called, the mapper first validates
the job, then looks up an entry in the MappingConfig table that corresponds to the job and
forwards it to the specified outgoing storage (a QueuingStorage object in the demo).
Before forwarding it though, the incoming ID (MappingConfig::blockId) needs to be mapped to an
outgoing block ID (MappingConfig::outgoingBlockId), which then gets assigned to a temporary
(outgoing) job. A temporary job is needed to avoid modifying the original one. Outgoing jobs are
configured with an “intermediate” callback implemented by the mapper. When an outgoing storage
eventually calls the intermediate callback, mapper then looks up the original job object from an
internal array and runs the user-provided callback.
Only a limited (but configurable) number of temporary job “slots” are available internally, so only a limited number of jobs can be delegated at once. If all outgoing jobs are already in use and another job is received, it will be added to a “waiting list”. As soon as one of the ongoing jobs finishes (i.e. the intermediate callback gets called), another job from the waiting list (if there are any) will be taken for processing in FIFO order.
There is also another internal list, used for storing jobs that have failed the validation in the
beginning of process() method. This list is needed because the user-provided callbacks need to
be called asynchronously and the corresponding jobs need to be remembered while this indirection
(an async::execute call) takes place. Running the callbacks directly instead could lead to
running out of stack memory if the user triggers additional jobs inside the callback.
Note
Besides the mapper, also QueuingStorage does internal queuing, so that additional jobs can
be received while the delegate storage is busy. In the demo setup, mapper can send as many jobs
as it has available slots, regardless if the QueuingStorage is already processing a job or
not. It’s important to keep in mind that since intrusive linked lists are used, each job object
can only appear in one list at a time (and only once in that list). This is one of the reasons
why sending the same job multiple times is forbidden: trying to queue it more than once wouldn’t
work.
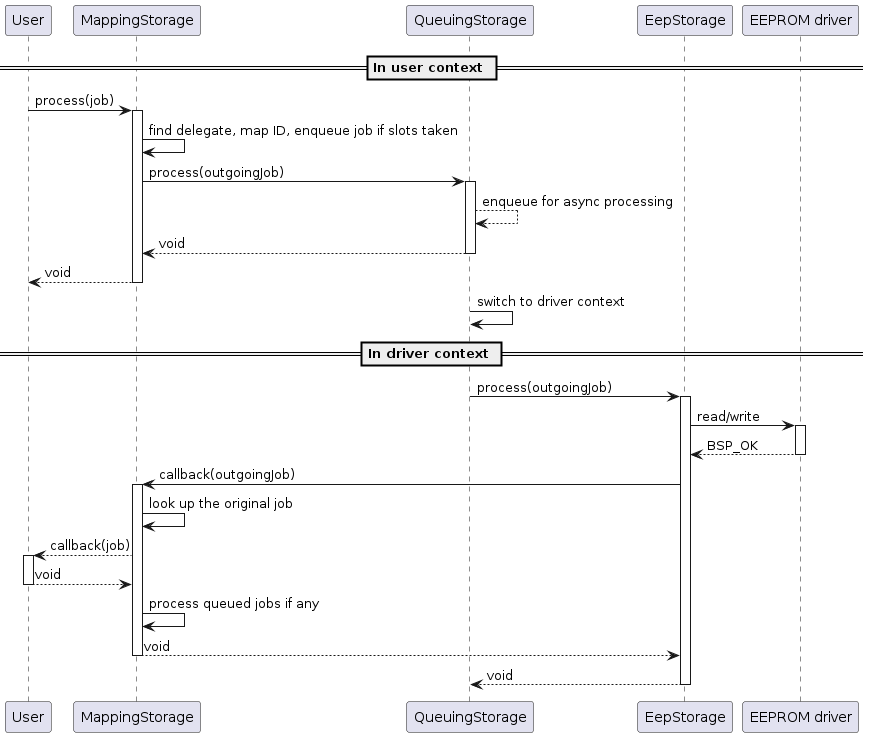
To illustrate how jobs are processed, a sequence diagram of a successful read or write job is shown below:
Advanced: rearranging the storages
The purpose of the common IStorage interface is to make it easier to support new use cases by
just rearranging the storages. For example, in single-user systems, thread safety is not a
concern, so there’s no need to switch to another context before calling a low-level storage. This
means that QueuingStorage can be left out and have the mapper call the storages directly
instead, so that everything (including the asynchronous callback) will be run in the same context.
This could also make sense on a very low-end hardware where applications must share resources and
work sequentially in order to save memory.
In case the mapper has only one delegate, it’s possible to leave the mapper out and have users call a queuing storage instead (in a multi-user system) or the underlying storage directly (in a single-user system).
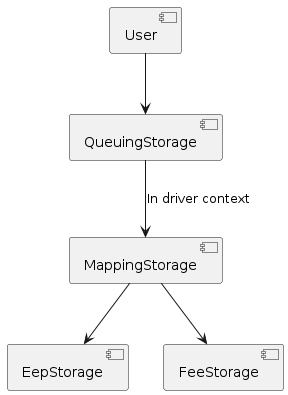
In case all storages can run in the same task context (but not in the user context directly), it’s also possible to have just one queuing storage and make the mapper act as its delegate rather than vice versa (remember, in the demo setup the queuing storages are delegates of the mapper). A diagram of this kind of setup is shown below:
Advanced: custom storages
Additional storages can also be implemented, for example:
storages for further physical device types (such as non-initialized RAM to retain data between restarts, or storing into a file if a file system is available)
an alternative storage implementation that defers writes until later (until sleep or shutdown, for example)
an alternative storage that uses less RAM for buffering but is slower, or vice versa
a storage that encrypts the data before storing it
a “safe storage” that holds the read data in an internal buffer, so that users can copy it in a safety-compatible way
a “proxy storage” that forwards jobs to another core, CPU or over the network
an adapter that translates storage API calls to a legacy API
an alternative mapper that provides extra functionality like write-rate control, where too frequent writes to the same block get delayed artificially
In case a storage should reuse some functionality of another one, using composition (delegates) should be favored over inheritance, in order to avoid coupling subclasses with one specific base class.
It’s worth noting that the purpose of the storage API is to make it easy for users to write robust
application code, meaning that exposing users to new pitfalls or limitations should be avoided if
possible. For example, during process(), storages should keep the job object intact, so that
users can still recognize it in the callback and reuse it without extra effort. Also, all resources
needed for maintaining internal state should be statically allocated in advance, so that any
sporadic “out-of-resources” errors can be avoided.
If the storage access is inherently unreliable, for instance if a storage forwards requests over a network, then it must also implement an internal retry to avoid any sporadic errors. This might mean that in the worst case jobs can take quite long to finish (say, a few seconds or more). Such delays can happen with any storage though due to reasons beyond their control, like high CPU load caused by other, higher priority tasks. In any case, it’s important to keep applications robust against severe delays.
A proxy storage forwarding requests over the network:
![component User
component MappingStorage
component EepStorage
component ProxyStorage
component Server as [Remote server]
User --> MappingStorage
MappingStorage --> EepStorage
MappingStorage --> ProxyStorage
ProxyStorage --> Server : Over the network](../../../_images/plantuml-e3c2b223d00e9b4b415569bc7b5bb87af838e706.png)
Integration example
This chapter shows an example configuration with some data blocks and two underlying storages:
EepStorage and FeeStorage. The first one uses an EEPROM driver (i.e. an implementation of
IEepromDriver) for storing. The second one is still not implemented and will not actually
store any data for now.
Storage-related objects are bundled in a lifecycle system called StorageSystem. Since most
applications using the storage API are located in other systems, they can get access to
the API via StorageSystem::getStorage(), which returns a reference to the mapper object.
The snippet below shows the block configuration defined inside StorageSystem (copied from
executables/referenceApp/application/include/systems/StorageSystem.h):
static constexpr uint8_t EEP_STORAGE_ID = 0;
static constexpr uint8_t FEE_STORAGE_ID = 1;
static constexpr ::storage::MappingConfig MAPPING_CONFIG[] = {
{
0xa01, /* block ID (uint32_t) */
0, /* outgoing block ID (uint32_t) */
EEP_STORAGE_ID /* outgoing storage index (uint8_t) */
},
{
0xa02,
1,
EEP_STORAGE_ID
},
{
0xb01,
2,
EEP_STORAGE_ID
},
{
0xb02,
0,
FEE_STORAGE_ID
},
};
static constexpr ::storage::EepBlockConfig EEP_BLOCK_CONFIG[] = {
{
10, /* EEPROM address (uint32_t) */
8, /* size in bytes (uint16_t; without the 4-byte header) */
true /* error detection enabled? (bool) */
},
{
22,
1,
false
},
{
23,
5,
false
},
};
The mapper is configured with four blocks, each with a unique block ID. Entries must be sorted from smaller to bigger block IDs. These IDs will be needed later when initializing the job object.
The “outgoing block IDs” need to match the order of entries in the second table, where additional details like the EEPROM address and data size are configured. When configuring the address, make sure it doesn’t overlap with the previous block: it cannot be smaller than the address + data size + header size of the previous block. For blocks with error detection, the header size is 4 bytes, for others zero.
Note: even though it makes sense to keep EEP_BLOCK_CONFIG ordered from smaller to bigger EEPROM
addresses, this isn’t strictly necessary and the blocks can be in any order, as long as the
outgoing block IDs in the first table refer to correct indices.
FeeStorage is still not implemented and doesn’t have its own config yet.
Next, the various storage objects need to be declared. This is shown below:
::eeprom::IEepromDriver& _eepDriver;
static constexpr size_t EEP_CONFIG_SIZE
= sizeof(EEP_BLOCK_CONFIG) / sizeof(::storage::EepBlockConfig);
static constexpr size_t MAX_DATA_SIZE = 8; // largest size defined in EEP_BLOCK_CONFIG
::storage::declare::EepStorage<EEP_CONFIG_SIZE, MAX_DATA_SIZE> _eepStorage;
::storage::FeeStorage _feeStorage;
::storage::QueuingStorage _eepQueuingStorage;
::storage::QueuingStorage _feeQueuingStorage;
static constexpr size_t MAPPING_CONFIG_SIZE
= sizeof(MAPPING_CONFIG) / sizeof(::storage::MappingConfig);
::storage::declare::MappingStorage<
MAPPING_CONFIG_SIZE,
2 /* number of delegate storages */,
2 /* max simultaneous jobs */>
_mappingStorage;
::storage::declare::StorageTester<MAX_DATA_SIZE> _storageTester;
::console::AsyncCommandWrapper _asyncStorageTester;
Note that the sizes of the block configs need to be calculated and passed to the respective storages as template parameters.
The next snippet shows the construction of these objects (copied from
executables/referenceApp/application/src/systems/StorageSystem.cpp):
StorageSystem::StorageSystem(
::async::ContextType const driverContext,
::async::ContextType const userContext,
::eeprom::IEepromDriver& eepDriver)
: _eepDriver(eepDriver)
, _eepStorage(EEP_BLOCK_CONFIG, _eepDriver)
, _feeStorage()
, _eepQueuingStorage(_eepStorage, driverContext)
, _feeQueuingStorage(_feeStorage, driverContext)
, _mappingStorage(MAPPING_CONFIG, driverContext, _eepQueuingStorage, _feeQueuingStorage)
, _storageTester(_mappingStorage, driverContext)
, _asyncStorageTester(_storageTester, userContext)
{
setTransitionContext(driverContext);
}
void StorageSystem::init() { transitionDone(); }
void StorageSystem::run() { transitionDone(); }
Here, _eepStorage gets associated with EEP_BLOCK_CONFIG (a global constant) and the
EEPROM driver. The queuing storages get associated with the corresponding low-level storages and
the task context where those storages should run. Mapper gets associated with its own block config,
an “error context” and the outgoing storages (please pay attention to the order, more details in
the warning below). The error context means the context where to run user-provided callbacks in
case the job or the configuration is invalid. If possible, use the same context that is used for
callbacks of successful jobs also, i.e. the one that was passed to the queuing storages.
After transitioning to the “run” state, the storage system is ready to receive jobs from users.
Warning
The order of outgoing storages passed to the mapper is crucial and must match the outgoing
storage indices used in MAPPING_CONFIG. In this case it means that _eepQueuingStorage
(storage index 0) must be passed before _feeQueuingStorage (storage index 1).
Example jobs
This chapter shows a small demo application where a block is loaded into RAM at startup, updated and then partially written back into EEPROM. If no existing data is found when reading, the RAM buffer will be initialized with zeros.
The demo code is located in the DemoSystem, which contains examples for other OpenBSW APIs
also. The read job is triggered in a cyclic call (DemoSystem::cyclic()) that is being called
every 10 milliseconds, and the write job is triggered in the provided callback after reading is
done. Please see the full code in
executables/referenceApp/application/src/systems/DemoSystem.cpp.
When DemoSystem::cyclic() gets called for the first time, a read job will be triggered like
this:
_storageJob.init(0xa01 /* block ID */, _jobDoneCallback);
_storageJob.initRead(_storageReadBuf, 0 /* start offset */);
_storage.process(_storageJob);
Note that block ID 0xa01 corresponds to one of the block entries in MAPPING_CONFIG from
before. Additionally, we specify the callback to be run in the end, the read buffer to read into
and the starting offset. Using offset 0 means that reading will start from the beginning of the
block, i.e. from EEPROM address 10 in this case.
The job is then sent for processing and eventually the callback will be run. The demo uses the following callback:
void DemoSystem::storageJobDone(::storage::StorageJob& job)
{
if (job.is<::storage::StorageJob::Type::Read>())
{
if (job.hasResult<::storage::StorageJob::Result::DataLoss>())
{
// data uninitialized or corrupt, initialize
(void)memset(&_storageData, 0, sizeof(_storageData));
}
Logger::debug(
DEMO,
"Storage read done, result=%d, size=%d, charParam0=0x%X",
(int)job.getResult().index(),
(int)job.getRead().getReadSize(),
_storageData.charParam0);
// update the data and trigger a write job
++_storageData.charParam0;
job.init(0xa01, _jobDoneCallback);
job.initWrite(_storageWriteBuf, 4 /* start offset */);
_storage.process(job);
}
else
{
Logger::debug(DEMO, "Storage write done, result=%d", (int)job.getResult().index());
}
}
The callback:
checks the job type and result
initializes the RAM data if the result indicates missing data (
Result::DataLoss)prints debug output about the read result
updates a variable inside the data
reinitializes the finished job as a write job and sends it for processing
finally, when the callback is run the second time, it prints another debug output
After this no more jobs will be triggered until the next startup. Note that the callback receives
the same job object as a parameter that was originally sent for processing (i.e. _storageJob in
this case). It’s also worth mentioning that even though job.init() is called here for
completeness, it could be skipped as well because the specified block ID and callback are the same
as for reading.
What’s different between reading and writing though are the used buffers and offsets. Even though
the whole block is read, only one byte is written back into the offset 4 (i.e. into the 5th byte).
This offset corresponds to the charParam0 variable. This is apparent when looking at the data
type of _storageData:
struct StorageData
{
uint32_t intParam;
uint8_t charParam0;
uint8_t charParam1;
uint16_t reserved;
};
Buffers with varying start addresses and sizes can be created as follows:
, _storageReadBuf(
::etl::span<uint8_t>(reinterpret_cast<uint8_t*>(&_storageData), sizeof(_storageData)))
, _storageWriteBuf(
::etl::span<uint8_t const>(reinterpret_cast<uint8_t const*>(&_storageData.charParam0), 1))
The read buffer (_storageReadBuf) is initialized with an etl::span covering the complete
_storageData. The write buffer, however, is initialized with a span associated with only one
byte. Notice also how uint8_t const is used as the write buffer data type because unlike the
read data, the write data won’t be modified by the storage module.